ICCV&NeurIPS 2023 |
您所在的位置:网站首页 › rec res › ICCV&NeurIPS 2023 |
ICCV&NeurIPS 2023
|
关注公众号,发现CV技术之美 本文转载自商汤学术。 摘要 · 看点 基于语言的多模态检测和分割近来受到了很多的关注,使得基于语言进行灵活、可泛化的检测成为了可能,在这种情况下,传统的基于类别的检测、分割数据集可能无法充分地评估和比较这些方法的能力。 本文介绍一个近期公开的基于语言描述的实例检测/分割数据集, ,即D-cube数据集,作为评估多模态检测/分割方法的一个新基准。该数据集具有以下几个特性: 类别名称是高自由度的语言描述,从简单的词到极长极复杂的句子 像COCO等检测数据集一样在所有图像上标注了所有类别的正负标签 关注语言中概念的缺席,例如“一只没有被绳索拴住的狗” 额外提供了按场景分组的模式,可以评估不同场景下的泛化性、分析模型识 难/易负样本的能力、切换zero-shot/few-shot设置 高精细度的实例mask标注 本数据集与传统的物体检测/分割相比,具有更强的挑战性,支持多种使用方式,且现有各类方法在该数据集上的效果还有很大的改进空间,欢迎尝试!
NeurIPS 2023
ICCV 23
背景和目标 现有的 (开放词汇) 检测/分割 (OVD/ OVIS) 数据集,如COCO、LVIS,和指向描述理解/分割 (REC/ RES) 数据集,如RefCOCO、RefCOCOg、RefCOCO+等,都有着各自的局限性。 开放词汇检测/分割任务,其检测或分割的目标只能是“某一类物体”,而不能是“具有某一属性/关系的物体”,缺乏对图片上下文的理解,不能利用语言去更精细地控制检测的目标和要求,在实际应用中灵活性达不到具体要求。 REC/RES任务虽然能够理解较长的、带有属性或关系的物体描述,但是假设图片中一定存在这样一个目标。对于实际不存在这一目标的图片,它没有拒绝和过滤的能力,会产生大量的假阳性(False Positive)误报结果,这对于实际应用来说是严重的问题。 以一个实际应用场景,即需要在工地里基于摄像头采集的数据检测“没有戴头盔的人”为例。一个OVD方法可以检测“头盔”“人”等物体并做到泛化,但是无法具体判定人和头盔的关系;而REC方法在任何一张图像上都会产生定位结果,在绝大多数情况下是误报,因此也不适用。现有的技术的解决方案是对这个流程进行拆解,需要用到多个专门的模型,且必须对每个场景定制化地采集数据、训练模型,大大脱离了实际,开发效率很低。 因此,基于语言描述的检测和分割存在显著的需求,即需要具有很强泛化能力的模型,能够根据任意的语言描述,判定图像中存不存在该语言描述对应物体并定位。 据此,我们提出了基于语言描述的实例检测/分割这一任务,以及相应的数据集, ,作为基准来验证模型完成这一任务并进行泛化的能力。这一任务具有广泛的应用场景,具体包括: 智慧城市,如检测“没有戴头盔的人”、“遛狗不牵绳”等 网络安全,如要在海量图像里检测敏感图片,如包含血腥、暴力的图片 照片相册的检索,或者是对海量网络图片数据进行过滤和检索 自动驾驶中特殊事件的检测,如“正在横穿斑马线的行人”等
数据集特点 完备标注 整个 数据集是完备标注的,即,对每个描述,像COCO一样,数据集中每张图片都被检查过并标注出可能的样本。下方的图片显示了针对两个不同的描述的部分标注结果,如对“partially damaged car”这一描述,第一行显示的是包含了损毁车辆的图片(包含该类别正样本),其中损毁车辆被标注了实例框和细致的分割mask,而第二行显示的是不包含部分损毁车辆的图片(仅包含该类别的负样本)。 这一完备标注的特性也使得本数据集与RefCOCO这类的REC/RES数据集,以及LVIS这样的联邦标注的检测数据集产生了显著的区别。之前的REC/RES数据集仅为每个描述标注出少量图片中的正样本,而剩余图片则没有标注出是否存在正样本或负样本。
数据集中各类别完备标注的正负样本 灵活描述 数据集中的类别是灵活的语言描述,既可以是“backpack“这样简短的类别名称,与之前的物体检测/实例分割数据集相似,也可以是非常长、非常复杂、包含从句的长句子,与之前的REC/RES数据集接近。 例如“a fisher who stands on the shore and whose lower body is not submerged by water”这一类别,包含了16个英文单词和包括“fisher”“stands on the shore”“lower body is not submerged by water”等多个属性,在语义上抽象、在视觉上多样。 也就是说,本数据集中对物体的描述是自由不受限的,包含了在REC/RES或物体检测/分割数据集里可能出现的各种类别名称。
数据集中类别对应描述可以是包括长句子和词语在内的高自由度语言描述 反向描述 本数据集还具备一个反向描述的特点,这一特点在之前的REC/RES或物体检测/分割数据集里都不具备,即部分描述类别被设计为反向描述。这里的反向描述指的是指明了某一物体或者属性的缺少(不存在)的描述。 例如,下方例子中的“没有被牵着的狗”,“教室里没有写上文字的黑板或白板”等。之所以专门设计反向描述这一特点,是因为检测/分割等相关技术在现实应用时,很多时候我们关注的不是某一物体或者属性的存在,而是其缺少,如在工地等场景需要自动检测“没有戴头盔的人”而不是“戴头盔的人”。 之前的模型往往对于这种物体或属性的缺少不敏感,现有的数据集也难以验证这一能力, 因此我们特意为这一数据集增加了这一特性。
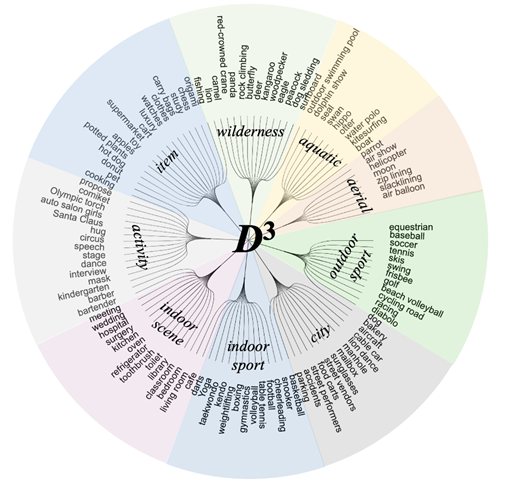
数据集中存在反向描述类别,重点突出某一概念的不存在 场景分组 本数据集对所有图片和描述做了分组,形成了超过100个来自不同场景类型(户外运动,城市,室内运动,野外环境等)的具体场景(骑马,棒球,足球等)。这样的分组使得使用者可以很方便地测试和对比模型的泛化能力,例如,在室内运动这一大类型中取得显著效果的模型,未必在野外环境这一大类型中还具有很强的性能。在论文中,我们未能对这些方面做深入的探索,因此该数据集这方面的特性还存在很大的探索和利用空间。 在标注数据集时,每个类别在其对应场景内和该场景外的图片上都做了完备标注。由于一个类别与其场景内的图片有更大的语义相关性,该场景内的负样本往往更难区分,因此,我们提出对每个类别在其场景内(Intra-scenario)和所有场景下(Inter-scenario)的两种评估方式,前者更关注数量相对少的难样本,后者则需要考虑所有场景中不同难度的样本,这也提供了更多的关于检测模型拒绝负样本的能力的分析空间。现有的方法在后面一种评估方式下性能极差(低于10 mAP),这是由于极为庞大的负样本数量导致的,这也说明了本数据集极大的挑战性。 精细的标注粒度
中一张图可以有零个到多个正样本 本数据集提供了实例级的物体框和mask的标注。值得注意的是: 一个类别在一张图中可以有多个正样本标注(当然,对负样本则是零个),如上图所示 mask的标注力度非常精细,如下图所示,与现有的RES数据集的标注粒度具有明显差别
RefCOCOg与 的mask标注精细程度对比图
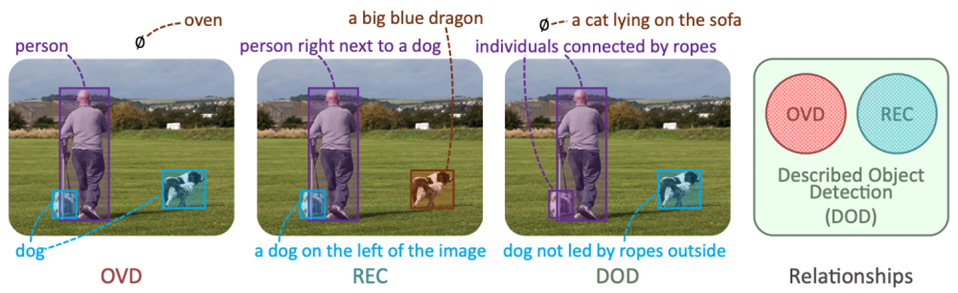
数据集所支持的任务 Described Object Detection/ Described Object Segmentation 我们的数据集支持基于语言描述的检测(Described Object Detection,DOD)这一任务。如下图所示,这一任务基于任意的语言描述,对图片中被语言描述的目标进行检测,需要做到定位图片中正样本的同时拒绝负样本图片,比OVD或者REC都更具有挑战性。类似地,由于本数据集同时具有实例mask的标注,它也支持基于语言描述的实例分割。 类似地,由于本数据集同时具有实例mask的标注,它也支持基于语言描述的实例分割(Described Object Segmentation,DOS)。这两者默认都是zero-shot的评估方式,即在其他数据集上训练模型,在本数据集上测试模型,重点考察模型的泛化能力。
本工作所介绍的基于语言描述的检测任务与OVD/REC等任务的关系 Referring Expression Comprehension/ Referring Expression Segmentation 本数据集同样也可以作为开放词汇检测和分割的基准,不同于之前的数据集的地方在于,这里的类别不仅仅是一两个单词构成的物体类名,也包含长而复杂的描述性句子。 因此,相比现有的OVD/OVS数据集,本数据集对于语言描述的细节和图像中物体的具体属性及关系的理解,提出了更高的要求。 Few-shot DOD/Few-shot DOS 本数据集保证了每个场景都具有一定数量的正样本图片。因此,该数据集除了现有的zero-shot评估(即在其他数据集上训练模型,在本数据集上测试)外,还可以进行few-shot评估,即使用每个场景的少量样本进行训练,在所有场景的剩余样本上进行测试。 这一任务形式我们并未在论文中做深入探讨,还存在更多的研究空间。
数据集具体信息 统计信息 我们所提出的数据集包含10,578张图片,都是从flickr网站上收集的。这些图片被划分为9个场景类型(户外运动、城市、室内运动、野外等)的106个组(骑马、棒球、足球等),每个组各包含大约100张图片并关联了4种描述,包括3个正向描述和1个反向描述(反向描述的定义和例子见上文“数据集特点”)。 每个组所关联的描述与该组所对应的场景高度相关,因此其描述的正样本在该组图片内大概率出现,在其他组图片内出现的概率较小。整个数据集有422个描述,包括316个正向描述和106个反向描述。
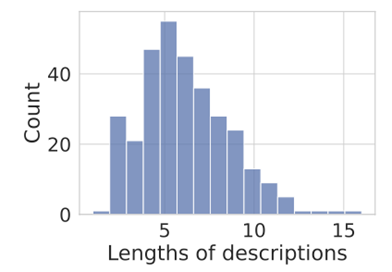
数据集类别的拓扑结构 对整个数据集,我们共标注了18,514个实例框及同样数量的实例mask。如上文所述,我们对数据集进行了完备标注,即对每个描述类别,在整个数据集的所有图片上都标注出了正样本和负样本。因此,这个数据集具有24, 282个正的物体-描述对和7,788,626个负的对。 在这大量的物体-描述对样本中,对应图像和描述来自不同场景的更可能是难样本,这种包含了20,279个正样本和53,383个负样本。本数据集中的描述的平均长度是6.3个单词,其长度分布如下图所示:
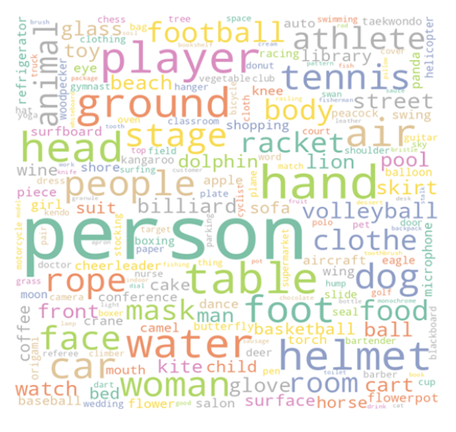
数据集中类别描述的长度分布 另外,本数据集具有丰富多样的词汇,如下方的词云所示。
数据集的 名词词云
数据集的 形容词词云
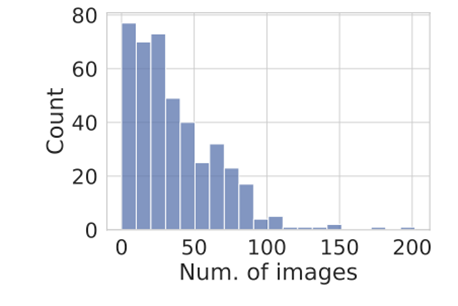
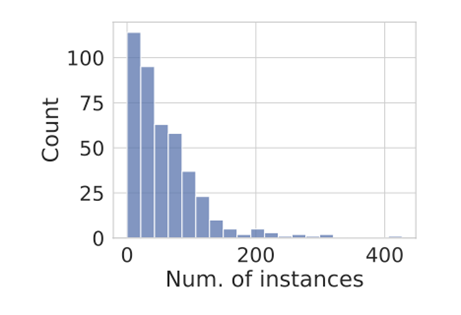
数据集的 动词词云 数据集中每个描述类别都对应着一定数量的正样本。每个描述对应的正样本图片和正样本实例数量如下图所示:
正样本图片数量分布
正样本实例数量分布
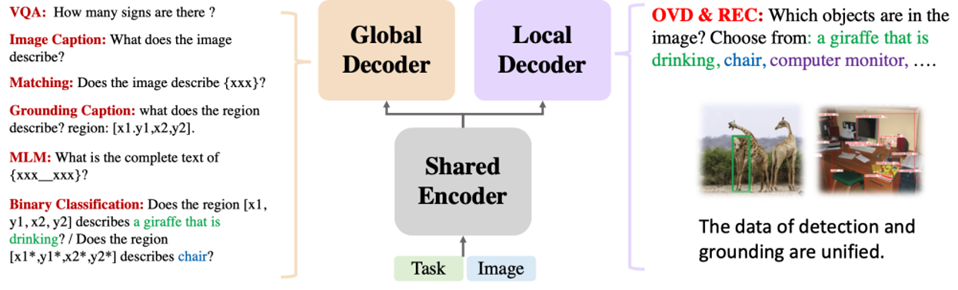
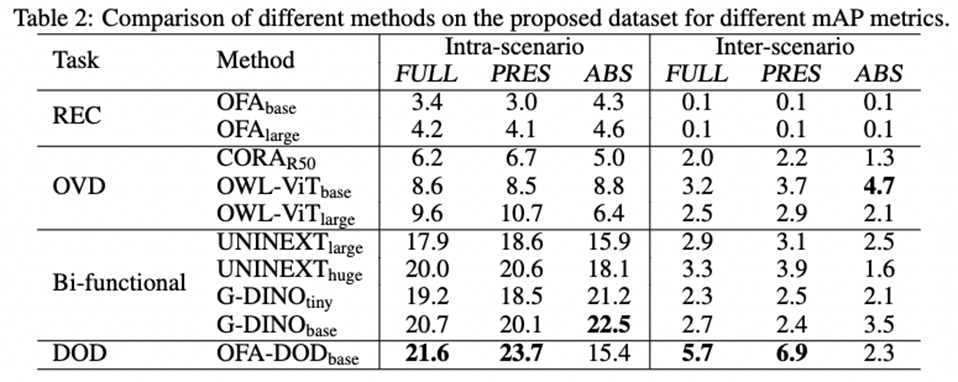
方法和实验结果 所提出的OFA-DOD方法 方法设计 在NeurIPS 2023的工作中,我们基于REC任务的State-of-the-art方法OFA,提出了一个适用于DOD任务的新baseline,OFA-DOD,其结构如下图所示。 我们关注到OFA用单个网络同时解决不同粒度的任务时,任务彼此之间的冲突,在结构上对OFA做了简单的扩展,将原本的单个适用于所有任务的解码器扩展为两个并行、结构相同的解码器,一者关注局部,负责基于描述定位局部区域;一者关注全局,负责基于文本和图像的全局特征判定描述和局部区域是否相匹配。另外,我们对REC和检测任务的数据进行了重构,使其形式统一为基于语言描述定位图像中任意数量的物体。 在训练和测试时,我们对DOD任务进行了拆分,以一个REC步骤(基于语言描述定位物体)和一个VQA步骤(判定定位框和语言描述是否匹配,本质上是二分类)完成它。
OFA-DOD方法示意图 实验结果 经过上述的简单修改,该基线方法在DOD上的性能得到了显著的增强。如下表所示,其性能超越了之前的REC方法的SOTA(如OFA),OVD方法的SOTA(OWL-ViT、CORA),以及同时进行OVD和REC任务的最新方法Grounding-DINO、UNINEXT等。
一些结果的可视化也在一定程度上显示了我们的方法能够更好地理解描述的句子语义(相对OWL-ViT这样的OVD模型)和拒绝负样本(相对OFA这样的REC模型以及Grounding-DINO)。
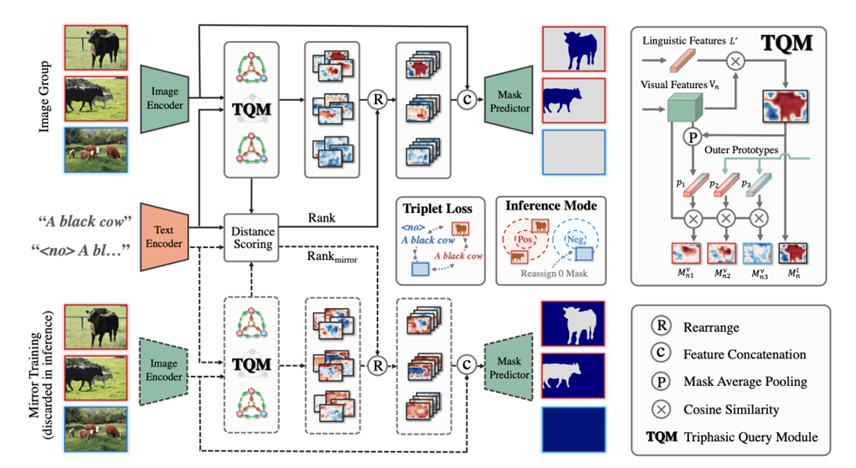
所提出的OFA-DOD方法与现有方法的检测结果可视化对比 所提出的GRSer方法 方法设计 在ICCV 2023的论文中,我们提出了一种方法GRSer,不同于之前的RES方法,其能够接收多张图片作为输入,输入图片可以存在、也可以不存在所描述的目标物体。
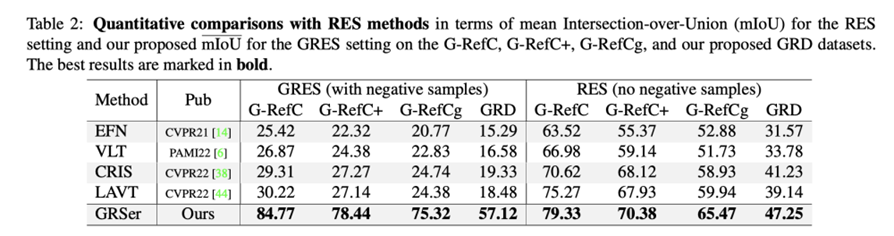
GRSer方法示意图 如图所示,GRSer方法支持单张或多张图像输入。在提出的三相查询模块(TQM)中,图像与指代文本间、同组图像间会分别进行特征交互,利用图像之间的特征交互对图文交互生成的目标热图(heatmap)进行二次优化,继而生产一系列热图。 接着,我们提出的热图排序模块(HH)会对生成的所有目标热图进行置信度排序,利用卷积的通道自适应权重特性,对生成的热图以不同的贡献值加权,从而实现对目标物体的精准定位和分割。 除此之外,我们还提出了一种镜像训练策略(Mirror Training),增强模型对于图像背景和反义语义的理解。 实验结果 我们的方法GREser在新提出的Group-wise RES和传统的RES任务上都取得了最佳性能。
针对模型中的关键设计,我们分别进行了消融可视化实验,结果如下图所示。可以看到我们的GRSer方法对于负样本图像具有很好的识别效果。
GRSer各模块ablation结果可视化分析
相关资料 论文地址: [NeurIPS 2023] Described Object Detection: Liberating Object Detection with Flexible Expressions: https://arxiv.org/abs/2307.12813 [ICCV 2023] Advancing Referring Expression Segmentation Beyond Single Image: https://arxiv.org/abs/2305.12452 数据集开源地址: https://github.com/shikras/d-cube/ 数据集下载地址: https://github.com/shikras/d-cube/releases/tag/v0.1.0-beta https://github.com/shikras/d-cube#download 数据集toolkit文档: https://github.com/shikras/d-cube/blob/main/doc.md 我们还维护了一个基于语言描述的检测分割工作的github awesome list,将会持续更新: https://github.com/Charles-Xie/awesome-described-object-detection
END 欢迎加入「目标检测」交流群👇备注:Det
|



















【本文地址】
今日新闻 |
推荐新闻 |